Earwax stickiness. Neanderthal ancestry. Caffeine metabolism. Tasting soap when you eat cilantro. Direct-to-consumer genotyping companies like 23andme boast this kind of information in exchange for a tube of your finest spit and a chunk of change about equivalent to a week’s worth of groceries. In the process of unlocking the whimsy of the human genome, however, companies that deal in providing genetic information to consumers have amassed an enormous collection of data.

Nearly 80% of 23andme’s consumers consent to have their information used for research purposes. One of the most valuable applications for information about millions of genomes and their owners is to uncover genes that can be targeted for therapies to treat diseases. A new multi-million-dollar collaboration between pharmaceutical company GlaxoSmithKline and 23andme promises to make identification of pharmaceutical targets quicker and aid in the design of therapies that are more likely to succeed in clinical trials on an unprecedentedly large scale.
But what does this have to do with whether you like the taste of cilantro? To find out, we first need to dive in to what kind of data direct-to-consumer genotyping companies have and how they get it.
In order to keep costs lower for the company and the consumer, most direct-to-consumer genetic testing companies use a simple method called a DNA microarray to test for specific snippets of the genome that are correlated with certain characteristics.

Source: NASA
To generate the DNA microarray, microscopic “spots” of DNA are linked to the surface of a tiny chip. These “probe” DNA sequences pair with specific sequences in the human genome that signify certain traits. Often, these specific sequences are portions of the genome where one individual may differ from another by a single nucleotide. The substitution of one base pair for another at a specific site in the genome is called a single nucleotide polymorphism, or a SNP. Many SNPs are commonly associated with specific traits, and are therefore a mainstay for direct-to-consumer genotyping companies. Only a fraction of existing SNPs are known to correlate with certain traits or diseases, limiting the number of probe sequences needed to test a single individual.
The company typically requests a saliva sample, which would contain both white blood cells and skin cells from within the mouth that are suitable for purifying large quantities of DNA. Once the saliva sample is received, DNA is extracted and subjected to an amplification process which generates more copies of the DNA from the sample. The DNA is then heated so that it no longer binds to its original pairing strand. Proteins that can cut DNA are then used to chop the genome into smaller pieces. From here, the DNA fragments are tagged with a unique fluorescent molecule that can track the position of the query DNA on the microchip. The processed sample is then applied to the chip, where query DNA will pair with probe DNA if it is complementary in sequence. To obtain test results, the microchip is analyzed for bright spots, which represent a positive test result for the genetic variant at that position on the microarray. Direct-to-consumer genetic testing companies typically include a catalog of probe DNA sequences that are strongly associated with specific traits, common ancestral backgrounds, and predisposition to a small subset of diseases.
So how can this information be useful to pharmaceutical companies? The answer is in the numbers. Associating features of the genome with traits or disease requires a large sample size to give the us more confidence that the association is real, and doesn’t simply occur because of random chance. Take the example of a SNP in the genome. Each human genome has about 10 million SNPs, or about 1 SNP per 300 base pairs. Some of these SNPs are insignificant and will be averaged out in the context of 2 million genomes. However, if a SNP is significantly associated with a disease, it will be found proportionally more often in genomes of people who have or are predisposed to having a disease compared to normal individuals. Pharmaceutical companies increasingly rely on finding new drug targets to develop new therapies, and are looking deeper into the genome to find new gene targets for therapies. Where to start? Genes with variations that correlate with certain traits or diseases –the exact information you can purchase from a direct-to-consumer genotyping service.
An approach to parsing these millions of genomes is referred to as PheWAS (phenome-wide association study). This study begins by looking at a genetic variant such as a SNP, and seeks to determine whether this variant is associated with a particular trait or set of traits in the individuals who have the variant. The data collected by direct-to-consumer genotyping companies are well-suited to be analyzed by PheWAS, as the companies often collect self-reported survey information on their customers. Myriad symptoms can be linked back to a single genetic variant with the power of huge genomic datasets to jumpstart the therapies of the future.
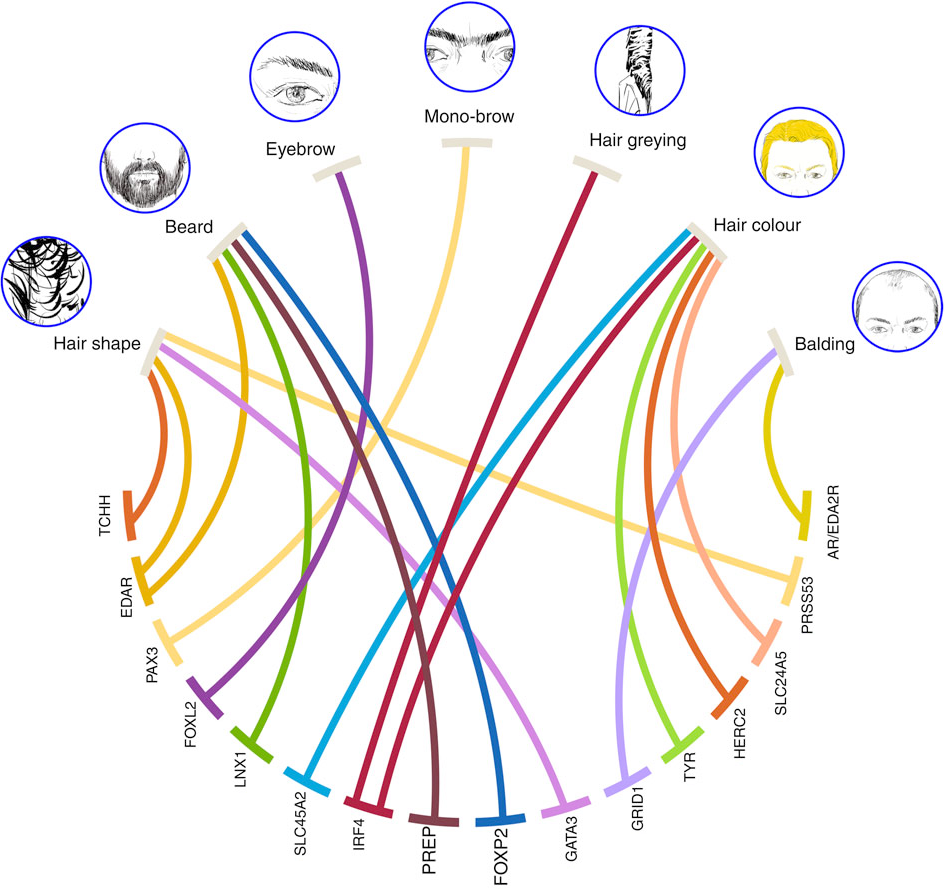
Source: Kaustubh Adhikari, T. F., et al. Nature Communications. (2016) (Wikimedia Commons)
Access to large databases of genotyping information may also give pharmaceutical companies further insight into more complex traits that are determined by a wide array of genes. An example of a complex trait is human height. There are a massive number of SNPs that contribute to the height of an individual. If you divide the genome up into ~30,000 equivalent-sized sections, nearly every one of these sections contributes to a person’s height. Many of the genetic variants that affect someone’s height are seemingly random and can only be identified by using large amounts of data. Similar to height, human disease is also connected to a combination of many genetic variants. It’s likely that pharmaceutical companies will begin looking not only at the genes that we think contribute to disease, but also throughout the rest of the genome for previously unknown variants that might be to blame. This information can be used to find new genes to target and help to avoid clinical pitfalls of previous drug strategies which were largely inefficient.
Despite the promises of big data in big pharma, it is unclear as yet whether or not partnerships between direct-to-consumer genotyping companies and pharmaceutical companies will be fruitful. Undoubtedly, developing drugs to treat diseases that have ineffective or nonexistent therapies is an attractive possibility. Furthermore, projects like these could promote a personalized medicine approach, where treatments are tailored to one’s specific therapeutic needs, as signified by their genome. An in-house effort within 23andme uses customer data to peg new drug targets. They claim to have uncovered 10 new targets for drug development. However, this collaboration raises the issue of consumers paying for the privilege of having their genomes used to garner profits for both their genotyping service and a pharmaceutical giant. A caveat to using such datasets is that the sample genomes mostly represent middle-to-upper-class individuals who live in Western countries, limiting the scope of the potential therapies developed as a result of the collaboration. Nevertheless, the marriage of genotype big-data and drug development holds exciting promise for the future of targeted therapies.
Peer edited by Jacob Pawlik and Giehae Choi.
Follow us on social media and never miss an article: